An Exploratory Study on Multi-modal Generative AI in AR Storytelling
Submitted to CHI 2025
Authorship: First Author
Abstract
Storytelling in AR has gained significant attention due it the multi-modality and interactivity of the platform. Research has introduced vast development in deploying multi-modal content in AR Storytelling. However, generating multi-modality content for AR Storytelling requires expertise and significant time for high quality and to accurately convey the narrator’s intention. Therefore, we conducted an exploratory study to investigate the impact of multi-modal content generated by AI in AR Storytelling. Based on the analysis of 223 videos of storytelling in AR, we identify a design space for multi-modal AR Storytelling. Derived from this design space, we have developed a testbed that facilitates both modalities of content generation and atomic elements in AR Storytelling. Through two studies with N=30 experienced storytellers and live presenters, we revealed the participants’ preferences for modalities to augment each element, qualitative evaluations on the interactions with AI to generate content, and the overall quality of the AI-generated content in AR Storytelling. We further discuss design considerations for future AR Storytelling systems based on our results.
Contribution
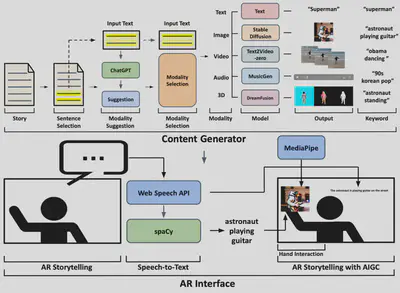
- Summarized a design space of multi-modal AR Storytelling and implemented a cognitive model for understanding the roles of authors and audiences in the storytelling process.
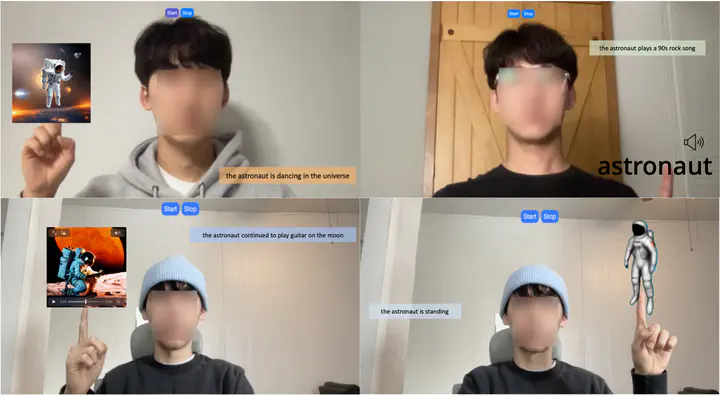
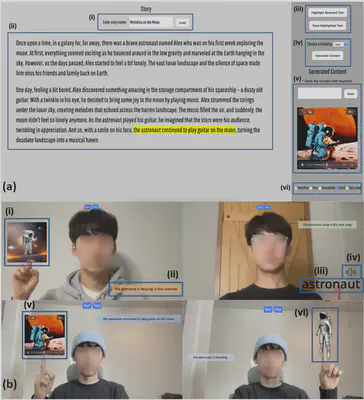
- Developed an experimental AR Storytelling testbed (Figure 2) with AI-generated multi-modal content, integrating with multiple state-of-the art generative AI models.
- Investigated the impact of AI-generated multi-modal content on the creation and perception of AR Storytelling through an exploratory study.
Hyungjun Doh
Master’s Student
My research interests are Human-AI interaction and its practical applications, with a specific focus on Extended Reality, Task Guidance Systems, and AI-infused interfaces.